Exercise repository for the Numerical Linear Algebra for HPC course, Winter 2020.
This repository provides a framework (with building and testing) for you to write
your code, allowing you to concentrate on the kernel implementation and the
performance benchmarking.
Build instructions
We use cmake to build the framework. Therefore, all you need to do is setup and build is
to clone this repository and within the directory,
mkdir build && cd build && cmake -DNLA4HPC_KIT_UNAME=<your kit uname> -DNLA4HPC_HW=<the HW number you are trying to compile> ..
Adding your own code.
Please create a separate repository for each hw. pr_hw0_build for HW0, pr_hw1_build for HW1 and so on.
First, please set the main exercises/ repository as the upstream repository
Every once in a while or when you see that the repository has been updated with new commits, do a git fetch upstream to get
the changes from the upstream repository into your local system.
Then, assuming that you have not any changes outside of the uxxxx0 directory, when you are on your pr_hwX_build you
should directly be able to do
In case there were changes in the specific uxxxx0 directories, then you can merge the changes, but please overwrite any of
your changes outside of this directory with the commits from the upstream. This makes merging to the master much easier later.
All homeworks have the following structure:
hwX
\|
\|
uxxxx0 (your pseudonym)
\|
\|-- include
\| \|
\| \|-- hwX.hpp (contains the function and class definitions)
\|
\|-- src
\| \|
\| \|-- hwX.cpp (contains the implementations themselves (ADD YOUR CODE HERE!))
\|
\|-- tests
\| \|
\| \|-- hwX.cpp (contains the unit tests for the hwX/hwX.cpp functions, update your tests here.)
\|
\|-- benchmark
\|
\|-- hwX.cpp (contains the benchmarks for the hwX/hwX.cpp functions, update your benchmarks here)
See the instruction sheet for each of the HW for more details and the README.md files within the hwX folders should also provide you with more information.
Working with CUDA and GPUs
Homeworks 5 and 6 require the CUDA Toolkit. A helper library called the CudaArchitectureSelector is used to detect the existing CUDA architectures and pass the appropriate flags. You can tweak the architectures by modifying the NLA4HPC_CUDA_ARCHITECTURES flag which is set to Auto by default.
The CUDA Programming guide has detailed information on how to program on NVIDIA GPUs. You can also refer to the corresponding lecture slides for more references.
Some general tips
Working with Ginkgo.
For these HW’s we would like you to not use Ginkgo and its functionalities in
your code, but use them only for the correctness checks. Nevertheless, detailed
documentation on Ginkgo is available through the Ginkgo repository.
If your tests cannot seem to find ginkgo, you may need to update your LD_LIBRARY_PATH to add the library path of Ginkgo.
If for example, Ginkgo has been installed in Ginkgo_DIR, then you can set the LD_LIBRARY_PATH with export LD_LIBRARY_PATH=$Ginkgo_DIR/lib:$LD_LIBRARY_PATH.
If you already have Ginkgo installed.
If you have Ginkgo installed or you are having some issues with installation with the third_party/ginkgo, you
can export Ginkgo_DIR=/path/to/ginkgo/installation and for the cmake step use
This repository contains dataset and communities generated based on the technique explained in our paper: "Finding Semantic Relationships in Folksonomies", published in IEEE/WIC/ACM International Conference on Web Intelligence 2018.
- Folders starting with prefix "E_" contains communities and pajek network files generated for each model used to represent tags.
- Co_occ folder contains communities of baseline.
- manual_communities folder contains communities created by authors.
- dataset folder contains:
1. sof_tags: tags used in our experiments to find communities
2. WIKI_sof: wikipedia articles related to Stack Overflow tags. Extracted from Wiki of Stack Overflow tags
3. CAT_sof: Wikipedia category links related to Stack Overflow tags
4. CAT_sof_llda_keywords: labeled LDA keywords generated for Wikipedia category links
5. E_excerpt: excerpts of tags, stopwords removed and words stemmed
6. E_llda: keywords generated by labeled LDA for each tag
7. E_wiki: labeled LDA keywords for cateogry links related to each tag
- qualitative_analysis.xlsx file contains details of quantitative and qualitative results of our approach (explained in discussion section of the paper).
- Trained Glove models can be downloaded from the following link: https://goo.gl/MK6Cnt and contains the following files:
1. Stack_Overflow_Data_score_positive_Content_Words_Stem_Glove_2.vectors.txt.w2vec: word vectors of Glove trained using SOF_we dataset
2. Stack_Overflow_Data_score_positive_tags_Glove_vec_min_count_10.vectors.txt.w2vec: word vectors of Glove trained using co-occurring tags only in SOF_we dataset.
3. wiki_embeddings_Glove_vec_min_count_10.vectors.txt_w2vec: word vectors trained using WIKI_we dataset.
Welcome to my data analytics capstone project on IBM!
I assume the role of a Data Analyst for a large international IT and business consulting organization that is renowned for its knowledge of IT solutions and its staff of highly skilled IT experts. The company frequently analyzes data to help determine future skill requirements in order to be competitive and keep up with rapidly evolving technologies.
I will be supporting this program as a data analyst, and I have been given the responsibility of gathering information from various sources and spotting trends for this year’s report on developing skills.
So each process in analysing the data is stored in the Jupyter notebooks that are uploaded.
Week 1 data collection
My first task is to gather a list of the most in-demand programming skills from job advertising, training websites, and polls, among other sources. In order to gather data in many formats like.csv files, excel sheets, and databases, I will start by scraping internet websites and using APIs.
Week 2 data wrangling
Data wrangling techniques will be used to prepare the acquired data for analysis.
Week 3 exploratory data analysis
Once I’ve retrieved and cleaned enough data, I will use statistical methods to analyze the data.
Week 4 data visualisation
Involves creating charts and graphs to visualize the data
Week 5 building a dashboard
I’ll use IBM Cognos Analytics to build a dashboard that will compile all of the data and nd spot trends and insights that might include the following:
Which programming languages are most in demand today?
What are the most in-demand database skills?
Which IDEs are the most popular?
Week 6 presentation of findings.
I use storytelling to share my findings in a presentation.
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
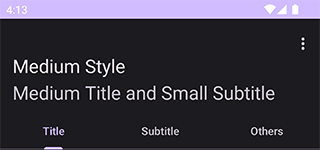
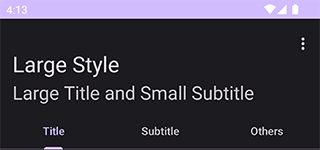
A carbon copy of CollapsingToolbarLayout
with subtitle support. During collapsed state, the subtitle would still appear
as Toolbar’s. There should be no learning curve because it works just like
CollapsingToolbarLayout. Supports Material Design 3 styling.
But because this library uses restricted APIs and private resources from Material Components,
there are a few caveats:
Only safe to use with the same version of material components.
Deceptive package name.
Also…
It is detabable if we even need this library. If the material guidelines says
it’s ok to have a subtitle in toolbar layout, then they surely would’ve already
implemented such feature. If it doesn’t say anything about subtitle (which is
odds because Toolbar has it), then we probably shouldn’t use it out of respect
to the guidelines.
Moleculegen-ML[1] is a Python package for de novo drug design based
on generative language modeling. It comprises tools for molecular data processing,
SMILES-based language modeling (recurrent networks, autoregressive transformers, convolutional networks) and transfer learning.
Documentation
For now, our wiki serves as a
documentation (or rather a user guide) for the project. Our paper [1] is a
survey of various machine learning methods for SMILES-based molecule generation.
If you find Moleculegen-ML useful in your research, please consider citing
[1].
Installation
It is convenient to set up dependencies using environment management systems like
conda or
virtualenv.
We use the latest stable version of Ubuntu to test our project.
We provide the benchmarking script scripts/run.py. To observe the command line
arguments print a help message:
$ python3 run.py --help
The paper uses standardized ChEMBL data from
[4]. If you wish to experiment with your own dataset, consider also the
preprocessing scripts in queries/ and scripts/.
Rotary button no longer is an action, instead it turns on/off the displays
Macros for Blender, Safari, MIDI drum kit, generic number pad and Zoom
Support for HID consumer control codes
Support for mouse buttons
Support for sending MIDI notes
When no HID connection is present (power only), keep LEDs off and provide a message
Mount filesystem as read-only unless the encoder button is pressed on boot
Refactored the code to make it (maybe) easier to modify
Using
You use the Macropad Hotkeys much like the original Adafruit version,
with a few differences.
Use the dial to select the macro template you would like to use. The macros appear
in the order specified within each config file (see Configuration below for details).
Once you have the macro you like selected, you are free to hammer away at the keys.
Click the rotary dial to turn off the display & LEDs – click it again to turn it back on.
Note the keys continue to respond even when they are not lit.
Configuration
The macros/ folder has a list of macro templates to chose from, all of which
can be altered at your whim. First make sure to mount your Macropad in read/write
mode (see Updating) and then open up the .py examples in the macros/ folder. Note that each has a list of settings, including:
The name that will show at the top of the OLED display
The sequential order that it will be shown when rotating the encoder dial
A list of macros, sorted by row
Each macro consists of an LED color, a label to appear on the OLED display,
and a sequence of keys. A “key” can be text, a keyboard key, a consumer control
key (like play/pause), a mouse action, or a MIDI note. More than one key can
be specified in a sequence.
When installing Macropad Hotkeys for the first time, extract the latest MacroPad Hotkeys.zip
into a directory, then copy the contents of that extracted archive
into the CIRCUITPY drive that appears when you plug in your Macropad.
Ensure that the contents of the lib/ subdirectory are also copied – these are
the precompiled Adafruit libraries that power the Macropad.
Updating
After you first install this version of Macropad Hotkeys and reboot the Macropad,
the CIRCUITPY filesystem will be mounted as read-only. When mounting the device
as read-only, Windows and MacOS won’t complain if you unplug or reboot the device
without unmounting it, making it more like a regular old HID device.
To update or edit the code on the device, or to modify the macros, you first
need to reboot the device with the CIRCUITPY drive mounted in read/write mode.
To do that, reboot the device using the boot switch on the left of the
Macropad, and then after releasing the button immediately hold down the
rotary encoder button. You should see the text “Mounting Read/Write” quickly
appear on the screen, and then the CIRCUITPY drive will mount in read/write mode.
This is the latest iteration on the Attract project. We are building a unified
framework called Pillar. Pillar will combine Blender Cloud and Attract. You
can see Pillar in action on the Blender Cloud.
Note that we only use the WOFF and WOFF2 formats, and discard the others
supplied by Fontello.
After replacing the font files & config.json, edit the Fontello-supplied font.css to remove all font formats except woff and woff2. Then upload
it to css2sass to convert it to SASS, and
place it in src/styles/font-pillar.sass.
Make sure your /data directory exists and is writable by the current user.
Alternatively, provide a pillar/config_local.py that changes the relevant
settings.
and place them in pillar/web/static/assets/vrview. Replace images/loading.gif in embed.min.js with static/pillar/assets/vrview/loading.gif.
You may also want to compare their index.html to our src/templates/vrview.pug.
When on a HDRi page with the viewer embedded, use this JavaScript code to find the current
yaw: vrview_window.contentWindow.yaw(). This can be passed as default_yaw parameter to
the iframe.
Celery
Pillar requires Celery for background task processing. This in
turn requires a backend and a broker, for which the default Pillar configuration uses Redis and
RabbitMQ.
You can run the Celery Worker using manage.py celery worker.
Find other Celery operations with the manage.py celery command.
Elasticsearch
Pillar uses Elasticsearch to power the search engine.
You will need to run the manage.py elastic reset_index command to initialize the indexing.
If you need to reindex your documents in elastic you run the manage.py elastic reindex command.
Translations
If the language you want to support doesn’t exist, you need to run: translations init es_AR.
Every time a new string is marked for translation you need to update the entire catalog: translations update
And once more strings are translated, you need to compile the translations: translations compile
To mark strings strings for translations in Python scripts you need to
wrap them with the flask_babel.gettext function.
For .pug templates wrap them with _().
The primary objective of this project is to seamlessly integrate with the Exodus platform and leverage its robust API to establish connections with a diverse range of applications and services. This integration will unlock a multitude of opportunities for enhanced functionality, data sharing, and automation across various platforms. In this document, we will delve into the comprehensive details of this ambitious integration project.
Project Scope:
The project scope encompasses several key aspects, including but not limited to:
API Integration: We will work closely with the Exodus platform’s API to establish secure and reliable connections. This will involve a deep understanding of the API endpoints, authentication mechanisms, and data formats.
Application Compatibility: Our integration efforts will ensure compatibility with a wide array of applications and services, spanning different industries and use cases. This includes popular software suites, IoT devices, cloud services, and more.
Data Exchange: The project will facilitate the seamless exchange of data between the Exodus platform and connected applications. This will enable real-time data sharing, synchronization, and analytics.
Functionality Enhancement: By integrating with the Exodus platform, we aim to enhance the functionality of connected applications. This may involve adding features such as automated data backups, secure file transfers, and multi-platform notifications.
Security and Compliance: Security is paramount in this project. We will implement robust security measures to protect data during transit and at rest. Compliance with data privacy regulations, such as GDPR and HIPAA, will be a key consideration.
Scalability: The integration architecture will be designed to accommodate future growth and scalability. This ensures that additional applications and services can be seamlessly added to the ecosystem as the need arises.
Project Timeline:
The timeline for this project will be divided into several phases, including:
Planning and Analysis: In this initial phase, we will conduct a thorough analysis of the Exodus API and identify the integration requirements.
Development: The development phase will involve building the necessary connectors and middleware to enable communication between the Exodus platform and various applications.
Testing: Rigorous testing will be conducted to ensure the reliability, security, and performance of the integration.
Deployment: Once testing is successful, the integration will be deployed, and initial connections with select applications will be established.
Optimization: Continuous optimization and refinement will be carried out to enhance the integration’s efficiency and effectiveness.
Scaling and Maintenance: As more applications are integrated, the system will be regularly maintained and scaled to meet growing demands.
Requirements
To run your project, make sure you have the following requirements:
Python 3.6+
Flask framework
Exodus API access (API keys and access permissions)
…
Installation
To run and develop your project, follow these steps:
Set up the configuration file and add your API keys:
cp config.example.ini config.ini
Start the application:
python app.py
Open your browser and go to http://localhost:5000 to begin using the application.
Usage
Provide detailed instructions on how to use your project. Explain the steps users should follow to gain API access and make integrations.
Project Team:
To successfully execute this project, a dedicated team with diverse skills will be assembled. This team may include:
Project Manager – Cole Chandler
Software Developers – Jose West, Melvin Quinn
API Specialists – Lloyd Barton, Kyran Gibbs
Security Experts – Ajay Ayala, Lloyd Barton
Project Benefits:
The successful integration with the Exodus platform will bring numerous benefits, including:
Streamlined data sharing and automation across various applications.
Improved productivity and efficiency for users of connected applications.
Enhanced data security and compliance with industry regulations.
Scalability to accommodate future growth and new applications.
Potential for revenue generation through premium features and services.
API Documentation
For more information on using the Exodus API, refer to the API documentation.
Contributing
If you’d like to contribute to this project, please follow these steps:
Fork this project.
Create a new branch: git checkout -b feature/your-feature-name
Commit your changes: git commit -m 'Add new feature'
Publish your changes in your fork: git push origin feature/your-feature-name
Open a pull request.
Conclusion:
The integration with the Exodus platform represents a significant opportunity to create a robust and interconnected ecosystem of applications and services. This project will require careful planning, technical expertise, and a commitment to delivering a secure and reliable integration solution. As we embark on this journey, we anticipate unlocking new possibilities and delivering substantial value to our users and partners.
Open source code is a fundamental pillar of our project’s success, especially in our integration with the Exodus platform. It embodies our dedication to transparency, collaboration, and innovation. In this discussion, we will delve into the significance of open source code and how it benefits both our project and the wider developer community.
Transparency and Accountability:
Open source code brings unparalleled transparency to our project. By providing public access to our source code, we establish trust with users, partners, and stakeholders. Anyone can review the code to ensure it adheres to best practices, security standards, and ethical guidelines. This transparency holds us accountable for the quality and integrity of our integration solution.
Community Collaboration:
The essence of open source projects is community collaboration. By open-sourcing our code, we invite developers from around the world to contribute their expertise, ideas, and enhancements. This collective effort accelerates development, resolves bugs, and introduces innovative features.
Knowledge Sharing:
Openly sharing code promotes knowledge exchange. Developers can gain insights into integration strategies, API interactions, and best practices by studying our codebase. This educational facet of open source benefits both seasoned developers and those looking to enhance their skills.
Flexibility and Customization:
Open source code empowers users to tailor the integration to their specific needs. They can modify the codebase to seamlessly integrate with their unique set of applications and services, thus ensuring the solution aligns precisely with their requirements.
Cost-Efficiency:
Open source code can dramatically reduce development costs. Leveraging existing open source libraries, frameworks, and components expedites development while keeping expenses in check. This cost-effectiveness is particularly valuable for projects operating within limited budgets.
Long-Term Sustainability:
Open source code offers the promise of long-term sustainability. Even if the original development team evolves or disbands, the open source community can continue to maintain and enhance the codebase. This guarantees the integration remains viable and up-to-date.
Licensing and Legal Compliance:
When sharing code as open source, selecting an appropriate open source license is crucial. This license clarifies how the code can be used, modified, and distributed, ensuring legal compliance while safeguarding intellectual property rights.
In conclusion, embracing open source code as a fundamental aspect of our integration project with the Exodus platform aligns seamlessly with our commitment to transparency, collaboration, and innovation. By doing so, we not only elevate the quality and sustainability of our integration but also contribute significantly to the broader developer community. This fosters a culture of shared knowledge and progress. Open source code stands as a cornerstone of our project’s success, with a positive impact extending throughout the technology landscape.
License
This project is licensed under the Project License. For more details, check the license file.















{kind=link}